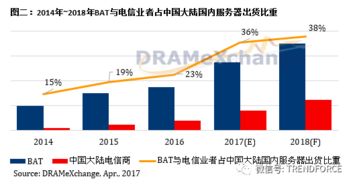
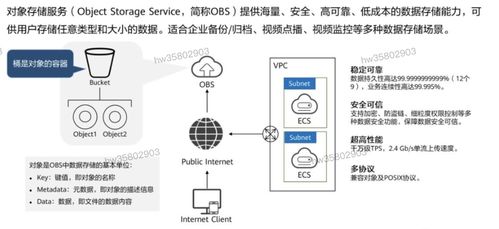
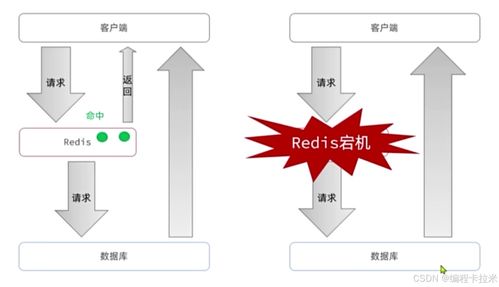
計算與存儲分離 解鎖數據處理與存儲服務的新范式
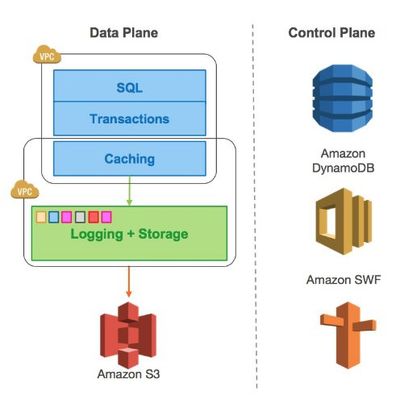
在數字化轉型的浪潮中,數據處理和存儲服務正經歷著一場深刻的架構變革。計算與存儲分離(Compute-Storage Separation)作為一種新興的設計范式,正逐漸成為構建高效、彈性、可擴展數據平臺的核心思想。它不僅重塑了數據處理流程,更深刻影響著數據服務的未來形態。
一、核心概念:解耦的力量
計算與存儲分離,顧名思義,是將數據計算(數據處理、分析、運算)和數據存儲(持久化保存)從傳統緊耦合的單一系統中解耦出來,成為兩個獨立可擴展、可管理的服務層。在傳統架構中,如典型的關系數據庫,計算節點通常與存儲綁定,擴容時往往需要同步增加計算和存儲資源,造成資源浪費和靈活性不足。而分離架構允許計算層和存儲層根據各自需求獨立伸縮,按需付費,顯著提升了資源利用率和系統彈性。
二、數據處理服務的革新:從批處理到實時流
在計算與存儲分離的架構下,數據處理服務迎來了前所未有的靈活性。計算層可以專門針對不同類型的計算任務進行優化:
- 批處理計算:如Apache Spark、Flink的批處理作業,可以從共享的存儲層(如對象存儲S3、HDFS)直接讀取海量數據,進行計算后,再將結果寫回存儲。計算集群無需持久化存儲數據,任務結束后資源即可釋放,極大降低了成本。
- 實時流處理:流處理引擎可以持續消費來自消息隊列的數據流,進行實時分析,并將中間狀態或最終結果寫入獨立的存儲服務。計算資源的彈性伸縮能力使得系統能夠輕松應對流量高峰。
- 交互式查詢:如Presto、Trino等引擎,通過分離架構,可以實現對海量數據的即席查詢,計算節點作為無狀態服務,從統一的數據湖或數據倉庫存儲中獲取數據,查詢性能和并發能力得到大幅提升。
三、存儲服務的演進:統一、持久與兼容
分離架構中的存儲層,承擔著數據持久化、高可用、高可靠的核心職責,并呈現出新的特征:
- 統一數據湖存儲:以對象存儲(如AWS S3、阿里云OSS)為代表,因其極高的持久性、近乎無限的擴展能力和低廉的成本,成為分離架構中存儲層的理想選擇。它提供了一個統一的數據存儲池,供各種計算引擎訪問。
- 數據格式與元數據管理:存儲層不僅存儲原始數據,還通過如Apache Iceberg、Hudi、Delta Lake等表格格式,在存儲層面提供了ACID事務、模式演化、時間旅行等高級特性,使得在簡單對象存儲之上構建企業級數據倉庫成為可能。
- 多協議與兼容性:現代存儲服務通常提供多種訪問協議(如S3、HDFS、文件系統接口),確保各類新舊計算引擎都能無縫接入,保護了現有技術投資。
四、核心優勢與價值體現
- 極致彈性與成本優化:計算與存儲可獨立伸縮。計算資源可按需快速啟動和釋放,應對波峰波谷;存儲資源則根據數據量平滑增長。這種按使用量付費的模式,避免了資源閑置,實現了顯著的TCO(總擁有成本)降低。
- 架構簡化與運維便利:解耦使得系統組件職責單一,降低了整體架構的復雜性。存儲服務的健壯性和持久性由云廠商或專業存儲軟件保障,計算層可專注于無狀態的計算邏輯,運維難度大大降低。
- 數據共享與一致性:所有計算引擎(批處理、流處理、交互式分析、機器學習)都訪問同一份存儲中的數據,消除了數據孤島和數據移動拷貝的需要,確保了數據的唯一性和一致性。
- 技術創新加速:計算層和存儲層可以獨立演進。新的計算框架可以快速利用現有數據資產,存儲層也可以持續升級而不影響上層應用,加速了整體技術棧的迭代創新。
五、挑戰與考量
盡管優勢明顯,計算與存儲分離的落地也面臨一些挑戰:
- 網絡性能瓶頸:計算節點頻繁從遠程存儲讀寫數據,網絡延遲和帶寬可能成為性能瓶頸。解決方案包括數據本地化緩存、計算靠近存儲的部署策略(如云上可用區親和)以及使用高性能網絡。
- 數據安全與治理:數據集中存儲后,訪問控制、加密、審計等安全治理措施需要貫穿整個數據鏈路,對權限模型和數據策略管理提出了更高要求。
- 生態工具適配:并非所有傳統數據處理工具都能天然適配分離架構,可能需要進行改造或選擇新的云原生工具。
六、未來展望
計算與存儲分離已成為云原生數據架構的基石。隨著存算一體芯片、可計算存儲、更智能的數據編排調度等技術的發展和融合,未來的數據處理與存儲服務將更加智能、高效和無縫。企業構建數據平臺時,采納這一范式,將能更好地應對數據量爆炸性增長、分析需求瞬息萬變的挑戰,真正釋放數據的核心價值。
計算與存儲分離不僅僅是一種技術架構選擇,更是一種面向云時代的數據管理哲學。它通過解耦帶來自由,通過獨立擴展實現效率,最終賦能企業構建出更敏捷、更經濟、更強大的數據驅動能力。
如若轉載,請注明出處:http://m.oilet.cn/product/59.html
更新時間:2026-03-19 07:12:05